All of this in an effort to test my migration script with changes in the hundreds. A quick recap:
1. Import metadata from production environment from 4 schemas. This includes mapping all the tablespaces from production to USER in my sandbox.
2. Create restore point.
3. Run build script.
4. Check for errors, fix errors
5. Flashback database to pre-deployment state.
6. Rinse and repeat as necessary.
If you have read any of those other posts, you'll know that:
a. I'm an idiot.
b. I like to guess.
3. I performed my first "recovery."
d. I learned the basics of Data Pump.
e. I like to break things.
For #1 above, import metadata, I've learned some hard lessons. I've had to repeat this step a number of times because I've either corrupted my database or dropped the restore point before flashing back.
And just now, a colleague of mine helped me out with another problem. See, the import process was extremely slow. Part of the reason (I think) I corrupted the silly thing was because I was mucking around at a level I don't quite understand...storage.
I just sent this pic to him:
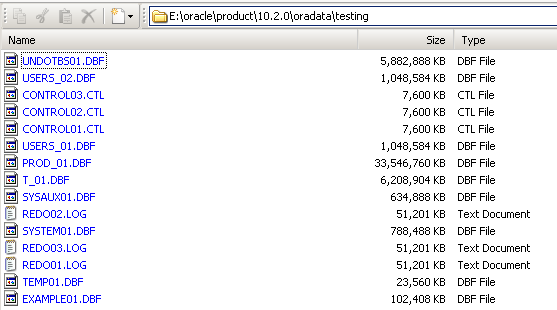
I was like, "WTF? Why do I need a 33GB datafile for metadata?"
Him: "Ummm...idiot...it preallocates the space which is based on production."
Me: <crickets>
Me: "How can I change the storage characteristics?" (I sent him the link to the Data Pump docs.)
Me: "How about this?" (Link to the TRANSFORM clause)
Aha...TRANSFORM has 4 options:
1. SEGMENT_ATTRIBUTES (Y, Default, to keep them, N to toss 'em)
2. STORAGE (Y, Default, to keep them, N to toss them)
3. OID
4. PCTSPACE
Where does RMAN fit into all of this? I'm not really sure. Last night I issued
RECOVER DATABASE;and it worked perfectly. Now, once I get an import completed, I take a backup of the tablespace. (I've since created a separate tablespace for the 2 largest schemas being imported.) That way, if I drop the restore point before flashing back, I should be able to restore it back to it's original state.
One of these days I'll get around to virtualizing all of this. I imagine that has to be easier, import the data, take a snapshot, run the script, fix, revert to previous snapshot. If I did that though, I wouldn't get to play (learn) with all of these cool tools.
No comments:
Post a Comment